
When I set out to build imgix 6 years ago, I was very aware that we were asking our customers to trust us with something fundamental to their success: the visual performance of their product. To earn that trust, we need to provide the best value, performance, and reliability.
Sadly, we have failed in that commitment over the last few weeks. Our performance has not been at the level our customers demand of us. Worse, with the entire team working around the clock to fix these problems, we have been unable to communicate what was happening. This is unacceptable to me.
I want to personally apologize to any customer who felt that imgix did not value their business during this time. We built imgix to enable our customers to do great things, and that partnership must always be built on trust and open communication.
In that spirit, I want to speak bluntly about the issues we have had, explain why they happened, and let you know what we are doing to make things right. A number of factors have contributed to imgix's recent performance problems. We have solved some of them, and are working hard on the remaining issues and taking further steps to keep situations like this from impacting our customers in the future.
So what happened?
A combination of incorrect capacity planning, architectural decisions that did not pan out, and just plain bad luck have contributed to imgix's ongoing performance issues over the past few weeks.
Capacity planning
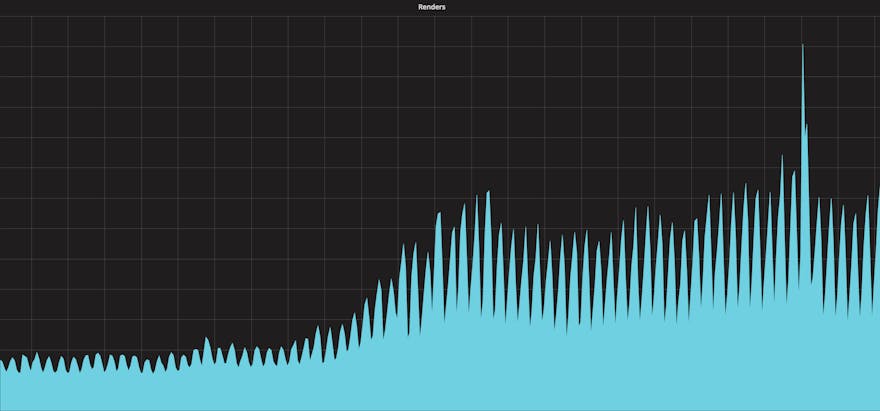
The biggest single factor is that imgix's rendering traffic has grown by 5x since the beginning of 2017. Our forecasts called for an increase of 1.5–2x over that period, and though we had headroom to spare, it proved not to be enough to prevent instability.
Architecture
imgix operates a specialized infrastructure built for the unique challenges posed by on-demand image processing at large scale.
We use off-the-shelf open source components as building blocks where it makes sense, but a fair amount of our architecture is custom-built. The decisions we made have been largely correct and have enabled us to offer compelling features at a great price point.
As our customers find new and innovative use cases for imgix, however, they sometimes fall outside of those we have optimized for. Recently we had an uptick in certain kinds of requests that proved to be more resource-intensive than we anticipated, and that took a toll.
Other factors
And then there is just bad luck. We have had a number of unlikely issues present themselves in quick succession:
Two of our long-time IP transit providers experienced issues with service delivery, which caused separate issues related to fetching content from S3 origins and serving some newly rendered content.
A critical piece of our network infrastructure failed after 3 years of correct operation in a way that proved difficult for our network engineering team to troubleshoot.
We observed new traffic patterns with significantly lower cache hit rates than our historical median, and it took us some time to determine whether the source was abusive in nature or a legitimate new customer use case.
What are we doing to fix it?
Since there is not just one issue, we are not doing just one thing. We are attacking the root problems from all available angles, and you should already see the improvements to imgix's performance and reliability.
Right now
More rendering capacity
In the last few weeks we increased our rendering capacity by 25%. We will add another 25% by the end of March, with the first batch of servers going online on March 21st.
Architectural improvements
The infrastructure engineering team at imgix has made a number of improvements to the architecture of imgix's rendering stack, and the systems it relies upon.
Increased capacity at our request targeting layer by more aggressively targeting repeat renders on the same master image to the same system. We have also augmented hardware capacity at the request targeting layer.
Optimized to improve certain edge cases where we were doing a lot more work than we needed to complete the request.
Increased capacity by 10–15% per render node by more aggressively reusing resources and improving the render cache hit rate (in conjunction with more aggressive request targeting).
Improved our GIF encoding pathway to increase throughput.
Better customer communication
You should never have to wonder whether imgix's service is performing correctly, whether it is by looking at our status dashboard (status.imgix.com), contacting your imgix account manager, or reaching out to imgix customer support.
We added a separate pager rotation just for updating our status page—because when something does go wrong, it is not practical to expect the person fixing the issue to also communicate with customers.
We have also made new hires on our customer support team, with the intention of providing broader business hours for support requests. With more coverage and a more targeted approach to support, we hope to be more responsive to every request and provide a higher level of service.
Origin cache capacity
Our rendering systems rely upon a caching tier that fetches content from customer origins and holds onto it. Usually this is a good thing, since it reduces the impact of sluggish or simply inconsistently performing origins, such as what happened during the recent Amazon S3 outage.
However, when the rendering tier becomes overloaded, it relies much more heavily on the origin cache than we had anticipated—so we must augment this as well. Short-term we have doubled the network throughput available from this tier and modestly expanded the cache storage size.
In April we will begin rolling out a new type of origin cache server that is an order of magnitude faster, albeit with less storage space. We will utilize both types of cache servers together in the near term, dividing them between content types. Over time, we will use them in a hierarchical fashion to accommodate particularly hot content. This will help alleviate problems caused by the cache layer.
More transit providers, more ways to fetch from origin and deliver
We are installing one new IP transit provider in our rendering facilities by the end of March. We are also taking steps to correct the issues identified over the past few weeks with two of our existing providers.
In addition, we are looking into other options for connecting to particularly popular services without using the commodity Internet to do so. This will give us more path diversity, and make our service less beholden to the whims of commodity routing.
Over time
Our near-term efforts go a long way toward addressing the issues in front of us. But we are not stopping there.
Aggressively hiring for key roles
We are continuing to expand the customer support team to better serve our customers, along with roles in account management, infrastructure engineering and other parts of the company. If you want to help make imgix more bulletproof, check out our jobs page (imgix.com/jobs).
Even more rendering and serving capacity
Though CDN performance has not been degraded, we will begin activating 6 new CDN POPs around the world in the next two months. This will give us better performance in several highly-requested regions, including Brazil. Your bandwidth price will not change. We are also planning to more than double our rendering capacity by expanding existing sites and adding new rendering locations in Q3 and Q4 2017.
Support for more backends beyond AWS S3
You can utilize imgix with any HTTP-speaking origin server, but by virtue of our S3 source type, a lot of our customer traffic originates at S3 (and particularly in the US Standard region). Over the next few months, we will launch native support for other cloud storage providers to better serve our customers and provide more diversity in our source origin traffic. This will make us less impacted by S3 instability, so we should perform even better during adverse events.
Better capacity planning
One thing we have learned is that not all image requests are equal, and some of them require more from our infrastructure than those we had seen in the past. We are going to incorporate the lessons we have learned into our capacity planning going forward. This work is ongoing and is always an inexact science, but we are committed to doing much better in the future.
Acknowledging that different types of image requests benefit from different handling techniques is a key takeaway that will inform our future product directions.
Summary
At imgix, we come to work every day to deliver the best image processing and delivery service to our customers.
It is hard work to operate a service at this scale, across a huge range of customer use cases, while maximizing performance and quality and still hitting the right price point. But that is no excuse for the problems we have had. We have not lived up our standards or yours over the past few weeks. I can only apologize, and promise you that we will do better in the future.
I cannot promise that we are completely out of the woods yet, but I am confident over the coming weeks you will see that we are building imgix into the ultra-reliable service it must be.
If you would like to talk more about this, please reach out to imgix support (support@imgix.com) or your imgix account manager and we will be in touch.




